Google’ın Algoritması
Google nasıl bir yapı ile kuruldu? Neleri referans aldı ve hangi kriterler ile nasıl bir algoritma çalıştırarak bu günlere geldi. Google’ın kurucuları Sergey Brin ve Larry Page’den arama motoru Google’ın anatomisi (Orjinal metnin Google Translate ile çevirilmiş halidir.)
Aşağıdaki çok çok uzun ve karışık metin Sergey Brin ve Larry Page’ın hazırlamış oldukları Google arama motorunun çalışma mantığı yani Google’ın algoritmasını anlatan orjinal çalışmadır. Bu çalışmayı okumaya başlamadan önce bilmelisiniz ki 1995 yılında Stanford Üniversitesi’nde Sergey ve Larry Google’ın atası olan Backrub’u kurdular. (Bknz. Google’ın Tarihi)
Google’ın Atası Backrub
Buraya kadar her şey normal gelebilir ancak işin ilginç yanı Google’ı Google yapan PageRank algoritması tamamen Backrub’a ait patentli bir algoritma olmasıdır. Tabi ki Sergey ve Larry’in yazmış olduğu bir algoritma ancak resmi olarak üniversitenin sahip olduğu bir patent. Okul sonrası Sergey bu algoritmanın patentini almaya çok çalışsa da maalesef alamamıştır. Sonraki zamanlarda Google fikri doğmuştur ve Backrub’a çok benzer bir çalışma mantığı ile Google hayata geçmiştir.
İlk Google Anatomisi
Yıllarca Google’ın algoritması yani anatomisi çok gizli bir bilgi olarak gösterildi. Hâlbuki bu algoritmanın temeli herkese açık bir şekilde yayınlanıyordu. Google’ın ilk algoritması tamamen Pagerank üzerine kurulu ve sitelerin birbirlerine verdikleri dış linkleri baz alıyordu. Ne kadar çok backlink almışsanız Google gözünde o kadar değerliydiniz. Google Pagerank hakkında daha fazla bilgiyi burada vermeyeceğim merak ediyorsanız Google PageRank hakkında uzun bir makalem zaten var.
Büyük Ölçekli Hipermetin Web Arama Motorunun Anatomisi
Aşağıdaki makale Google’ın Anatomisi Google’ın kurucuları olan Sergey Brin ve Larry Page’in Stanford Üniversitesi bitirme tezidir. Orijinal tezin yine bir Google ürünü olan Google Translate ile çevirilmesi ile Türkçe’leştirilmiştir. Meraklı bir SEO uzmanı mutlaka bu içeriği okumalıdır.
Abstract
Bu yazıda, hipermetin içinde mevcut yapıyı yoğun şekilde kullanan, büyük ölçekli bir arama motorunun prototipi olan Google’ı sunuyoruz. Google, Web’i verimli bir şekilde taramak ve dizine eklemek ve mevcut sistemlerden çok daha tatmin edici arama sonuçları üretmek için tasarlanmıştır. Tam metin ve en az 24 milyon sayfalık köprü veri tabanı içeren prototip http://google.stanford.edu/ adresinde bulunabilir.
Bir arama motorunu tasarlamak zor bir iştir. Arama motorları indexi, karşılaştırılabilir sayıda farklı terim içeren yüz milyonlarca web sayfasını gösterir. Her gün on milyonlarca soruyu yanıtlıyorlar. Büyük ölçekli arama motorlarının web üzerindeki önemine rağmen, bunlarla ilgili çok az akademik araştırma yapılmıştır. Ayrıca, teknolojideki hızlı ilerlemeden ve web proliferasyonundan dolayı, bugün bir web arama motoru oluşturmak üç yıl öncekinden çok farklı. Bu makale, geniş çaplı web arama motorumuzun derinlemesine bir açıklamasını sunar – bugüne kadar bildiğimiz ilk ve genel açıklamalı açıklama.
Geleneksel arama tekniklerinin bu büyüklükteki verilere ölçeklendirilmesinden kaynaklanan sorunların yanı sıra, daha iyi arama sonuçları elde etmek için köprü metni içinde bulunan ek bilgileri kullanmakla ilgili yeni teknik zorluklar vardır. Bu makale, köprü metni içinde yer alan ek bilgilerden faydalanabilecek pratik bir büyük ölçekli sistemin nasıl inşa edileceği sorusunu ele almaktadır. Ayrıca, herkesin istediği her şeyi yayınlayabildiği kontrolsüz köprü metin koleksiyonları ile etkin bir şekilde nasıl başa çıkılacağı sorununa bakıyoruz.
Anahtar Kelimeler : World Wide Web, Arama Motorları, Bilgi Edinme, PageRank, Google
1. Giriş
Web, bilgi alımı için yeni zorluklar oluşturur. Web’deki bilgi miktarı, web araştırma sanatında deneyimsiz olan yeni kullanıcı sayısının yanı sıra hızla artmaktadır. İnsanlar, genellikle Yahoo! gibi yüksek kaliteli insan kaynaklı endekslerden başlayarak, bağlantı grafiğini kullanarak web’de gezinme eğilimindedir veya arama motorlarıyla. İnsanoğlunun listeleri popüler konuları etkili bir şekilde kapsıyor, ancak öznel, pahalı ve inşa etmek, geliştirmek, yavaşlamak ve tüm ezoterik konuları kapsayamıyor. Anahtar kelime eşlemesine dayanan otomatik arama motorları genellikle çok düşük kalitede eşleşmelere neden olur. Sorunları daha da kötüleştirmek için, bazı reklam verenler otomatik arama motorlarını yanlış yönlendirmek için önlemler alarak insanların dikkatini çekmeye çalışır. Mevcut sistem sorunlarının çoğuna hitap eden büyük ölçekli bir arama motoru geliştirdik. Çok daha yüksek kaliteli arama sonuçları sağlamak için html içinde yer alan ek yapının özellikle kullanılmasını sağlar. Google, sistem adımızı seçtik, çünkü googol’ün yaygın bir yazımıdır veya 10 100 ve çok büyük ölçekli arama motorları oluşturma hedefimize çok yakışıyor.
1.1 Web Arama Motorları – Ölçeklendirme: 1994 – 2000
Arama motoru teknolojisi, web’in büyümesine ayak uydurmak için çarpıcı biçimde ölçeklendirmek zorunda kaldı. 1994 yılında, ilk web arama motorlarından biri olan World Wide Web Worm (WWWW) [McBryan 94] 110.000 web sayfası ve web erişimli dokümanlara sahipti. Kasım 1997’den itibaren, en iyi arama motorları 2 milyondan (WebCrawler) 100 milyon web dokümanına (Arama Motoru İzleme’den) endekslediğini iddia ediyor. 2000 yılına kadar kapsamlı bir Web endeksinin bir milyardan fazla belge içereceği tahmin edilebilir. Aynı zamanda, arama motorlarının ele aldığı sorgu sayısı da inanılmaz bir şekilde arttı. Mart ve Nisan 1994’te, World Wide Web Worm günde ortalama 1500 sorguyu aldı. 1997 yılının Kasım ayında, Altavista günde yaklaşık 20 milyon soru sorduğunu iddia etti. Web’deki artan kullanıcı sayısı ve arama motorlarını sorgulayan otomatik sistemler sayesinde, en iyi arama motorlarının 2000 yılına kadar günde yüz milyonlarca sorguyu ele alması muhtemeldir. Arama motoru teknolojisini bu olağanüstü sayılara ölçeklendirerek ortaya çıkan kalite ve ölçeklenebilirlik problemleri.
1.2. Google: Web ile Ölçeklendirme
Bugünün ağına bile ölçeklenen bir arama motoru oluşturmak birçok zorluğu beraberinde getiriyor. Web dokümanlarını toplamak ve güncel tutmak için hızlı tarama teknolojisine ihtiyaç vardır. Depolama alanı, indeksleri ve isteğe bağlı olarak belgeleri kendileri saklamak için verimli bir şekilde kullanılmalıdır. İndeksleme sistemi, yüzlerce gigabayt veriyi verimli bir şekilde işlemelidir. Sorguların saniyede yüz ila binlerce oranında hızla ele alınması gerekir.
Web büyüdükçe bu görevler giderek zorlaşıyor. Bununla birlikte, donanım performansı ve maliyeti, zorlukların kısmen dengelenmesi için önemli ölçüde iyileşmiştir. Bununla birlikte, disk ilerleme zamanı ve işletim sistemi sağlamlığı gibi bu ilerlemenin dikkate değer bazı istisnaları vardır. Google’ı tasarlarken, hem Web’in büyüme oranını hem de teknolojik değişiklikleri dikkate aldık. Google, son derece büyük veri kümelerine iyi ölçeklendirmek için tasarlanmıştır. Dizini depolamak için depolama alanını verimli şekilde kullanır. Veri yapıları hızlı ve verimli erişim için optimize edilmiştir (bkz. Bölüm 4.2 ). Ayrıca, metin veya HTML’yi endeksleme ve saklama maliyetinin sonunda kullanılabilecek miktara göre düşeceğini tahmin ediyoruz (bkz. Ek B).). Bu, Google gibi merkezi sistemler için uygun ölçeklendirme özellikleriyle sonuçlanacaktır.
1.3 Tasarım Hedefleri
1.3.1 Gelişmiş Arama Kalitesi
Asıl amacımız web arama motorlarının kalitesini arttırmak. 1994 yılında, bazı insanlar tam bir arama endeksinin kolayca bir şey bulmayı mümkün kılacağına inanıyordu. Web’in En İyisine Göre 1994 – Navigators, “En iyi navigasyon servisi, Web’de neredeyse her şeyi bulmayı kolaylaştırmalıdır (tüm veriler girildikten sonra).” Ancak, 1997’nin ağı oldukça farklı. Son zamanlarda bir arama motoru kullanan herkes, indeksin bütünlüğünün, arama sonuçlarının kalitesindeki tek faktör olmadığını kolayca söyleyebilir. “Önemsiz sonuçlar” genellikle bir kullanıcının ilgilendiği sonuçları temizler. Aslında, Kasım 1997’de, ilk dört ticari arama motorundan yalnızca biri kendini bulur (ilk 10’daki ismine cevaben kendi arama sayfasını döndürür). Sonuçlar). Bu sorunun temel nedenlerinden biri, endekslerdeki belge sayısının birçok büyüklük sırasına göre artmasıdır, ancak kullanıcının belgelere bakma yeteneği artmamıştır. İnsanlar hala sadece ilk birkaç onlarca sonucu incelemeye hazırlar. Bu nedenle, koleksiyon boyutu büyüdükçe, çok yüksek hassasiyete sahip araçlara ihtiyacımız var (sonuçta en fazla onlarca yazılan ilgili belgelerin sayısı). Gerçekten de, “ilgili” kavramının sadece en iyi belgeleri içermesini istiyoruz çünkü on binlerce hafif ilgili belge olabilir. Bu çok yüksek hassasiyet, geri çağırma pahasına bile önemlidir (sistemin döndüğü ilgili toplam belge sayısı). Daha fazla hipermetin bilginin kullanılmasının, aramanın ve diğer uygulamaların geliştirilmesine yardımcı olabileceği konusunda son zamanlarda iyimserlik var [ sadece en iyi belgeleri içermelidir, çünkü on binlerce hafif ilgili belge olabilir. Bu çok yüksek hassasiyet, geri çağırma pahasına bile önemlidir (sistemin döndüğü ilgili toplam belge sayısı). Daha fazla hipermetin bilginin kullanılmasının, aramanın ve diğer uygulamaların geliştirilmesine yardımcı olabileceği konusunda son zamanlarda iyimserlik var [ sadece en iyi belgeleri içermelidir, çünkü on binlerce hafif ilgili belge olabilir. Bu çok yüksek hassasiyet, geri çağırma pahasına bile önemlidir (sistemin döndüğü ilgili toplam belge sayısı). Daha fazla hipermetin bilginin kullanılmasının, aramanın ve diğer uygulamaların geliştirilmesine yardımcı olabileceği konusunda son zamanlarda iyimserlik var [Marchiori 97 ] [ Spertus 97 ] [ Weiss 96 ] [ Kleinberg 98 ]. Özellikle, bağlantı yapısı [ Sayfa 98 ] ve bağlantı metni, alaka düzeyi değerlendirmeleri yapmak ve kalite filtrelemek için birçok bilgi sunar. Google, hem bağlantı yapısını hem de bağlantı metnini kullanır (bkz. Bölüm 2.1 ve 2.2 ).
1.3.2 Akademik Arama Motoru Araştırması
Web, muazzam büyümenin yanı sıra, zaman içinde giderek daha da ticari hale geldi. 1993’te web sunucularının% 1.5’i .com alan adındaydı. Bu rakam 1997 yılında% 60’ın üzerine çıkmıştır. Aynı zamanda, arama motorları akademik alandan reklam alanına geçmiştir. Şimdiye kadar çoğu arama motoru geliştirme, teknik detayların az yayınlandığı şirketlerde devam etti. Bu, arama motoru teknolojisinin büyük ölçüde siyah bir sanat olarak kalmasına ve reklam odaklı olmasına neden olur (bkz. Ek A ). Google ile daha fazla gelişme ve anlayışı akademik dünyaya itmek için güçlü bir hedefimiz var.
Bir diğer önemli tasarım hedefi, makul sayıda insanın gerçekten kullanabileceği sistemler kurmaktı. Kullanım bizim için önemliydi, çünkü en ilginç araştırmaların bazılarının modern web sistemlerinden elde edilebilecek geniş kullanım verilerinin kullanılmasını içereceğini düşünüyoruz. Örneğin, her gün yapılan milyonlarca arama vardır. Ancak, bu verileri elde etmek çok zordur, çünkü esas olarak ticari olarak değerli kabul edilir.
Nihai tasarım hedefimiz, büyük ölçekli web verilerinde yeni araştırma faaliyetlerini destekleyebilecek bir mimari oluşturmaktı. Yeni araştırma kullanımlarını desteklemek için Google, taradığı tüm asıl belgeleri sıkıştırılmış biçimde saklar. Google’ı tasarlamadaki ana hedeflerimizden biri, diğer araştırmacıların hızla gelebileceği bir ortam oluşturmak, web’in büyük parçalarını işlemek ve aksi takdirde üretilmesi çok zor olan ilginç sonuçlar üretmek oldu. Sistem kısa süre içinde devreye girdiğinde, Google tarafından oluşturulan veri tabanlarını kullanan çok sayıda makale yayınlandı ve diğerleri de devam ediyor. Sahip olduğumuz diğer bir hedef, araştırmacıların hatta öğrencilerin bile büyük ölçekli web verilerimiz üzerinde ilginç deneyler önerebilecekleri ve yapabilecekleri bir Spacelab benzeri ortam oluşturmaktır.
2. Sistem Özellikleri
Google arama motoru, yüksek hassasiyetli sonuçlar üretmesine yardımcı olan iki önemli özelliğe sahiptir. İlk olarak, her web sayfası için kalite sıralamasını hesaplamak için Web’in bağlantı yapısını kullanır. Bu sıralamaya PageRank adı verilir ve [Sayfa 98] ‘de ayrıntılı olarak açıklanmaktadır. İkincisi, Google, arama sonuçlarını iyileştirmek için bağlantıyı kullanır.
2.1 PageRank: Web’e Sipariş Vermek
Web’in alıntı (link) grafiği, mevcut web arama motorlarında büyük ölçüde kullanılmayan önemli bir kaynaktır. Toplamın önemli bir örneği olan bu köprülerin 518 milyon kadarını içeren haritalar oluşturduk. Bu haritalar, web sayfasının “Sayfa Sıralaması” nın hızlı bir şekilde hesaplanmasına olanak tanır; bu, insanların öznel önemi konusundaki fikrine uygun olan atıf öneminin bir ölçüsüdür. Bu yazışma nedeniyle, PageRank, web anahtar kelime arama sonuçlarına öncelik vermenin mükemmel bir yoludur. En popüler konular için, sayfa sıralamasıyla sınırlı olan basit bir metin eşleştirme araması, PageRank sonuçları önceliklendirdiğinde ( google.stanford.edu adresinde mevcut olan demo) ön plana çıkar . Ana Google sistemindeki tam metin arama türlerinde, PageRank de çok yardımcı olur.
2.1.1 Sayfa Sırası Hesaplamasının Açıklaması
Belirli bir sayfaya yapılan atıfları veya geri bağlantıları saymak suretiyle, web’e akademik atıf literatürü uygulanmıştır. Bu, bir sayfanın önemine veya kalitesine bazı yaklaşımlar verir. PageRank, bu fikri tüm sayfalardan gelen bağlantıları eşit olarak saymayarak ve bir sayfadaki bağlantı sayısına göre normalleştirerek genişletir. PageRank şöyle tanımlanır:
A sayfasının, onu gösteren T1 … Tn sayfalarına sahip olduğunu varsayıyoruz (örn. Alıntılar). D parametresi 0 ile 1 arasında ayarlanabilen bir sönümleme faktörüdür. Genellikle d’yi 0,85 olarak belirleriz. Bir sonraki bölümde d hakkında daha fazla detay var. Ayrıca, C (A), sayfa A’dan çıkan bağlantıların sayısı olarak tanımlanır. A sayfasının Sayfa Sırası aşağıdaki gibi verilir:
PR (A) = (1-d) + d (PR (T1) / C (T1) + … + PR (Tn) / C (Tn))
PageRanks’in web sayfaları üzerinde bir olasılık dağılımı oluşturduğuna dikkat edin, bu nedenle tüm web sayfalarının PageRanks toplamının bir olacağını unutmayın.
PageRank veya PR (A) basit bir yinelemeli algoritma kullanılarak hesaplanabilir ve ağın normalleştirilmiş link matrisinin temel özvektörüne karşılık gelir. Ayrıca, 26 milyondan fazla web sayfasının PageRank’i birkaç saat içinde orta büyüklükte bir iş istasyonunda hesaplanabilir. Bu yazının kapsamı dışında kalan birçok detay var.
2.1.2 Sezgisel Gerekçe
PageRank, bir kullanıcı davranışı modeli olarak düşünülebilir. Rastgele bir web sayfası verilen ve bağlantıları tıklayıp, asla “geri” yi vurmadan, ancak sonunda sıkılıp, başka bir rasgele sayfada başlayan bir “rastgele sörfçü” olduğunu varsayıyoruz. Rastgele sörfçünün bir sayfayı ziyaret etme olasılığı PageRank’tir. Ve d sönümleme faktörü, her sayfada “rastgele sörfçü” den sıkılma ve başka bir rastgele sayfa talep etme olasılığıdır. Önemli bir değişiklik, sönümleme faktörünü d yalnızca bir tek sayfaya veya bir sayfa grubuna eklemektir . Bu kişiselleştirme sağlar ve daha yüksek bir sıralama elde etmek için sistemi kasten yanlış yönlendirmeyi neredeyse imkansız hale getirebilir. PageRank’e birkaç ek uzantımız var, tekrar bakın [ Sayfa 98 ].
Bir başka sezgisel gerekçelendirme, bir sayfaya işaret eden çok sayıda sayfa varsa veya onu gösteren ve yüksek bir PageRank olan bazı sayfalar varsa yüksek bir PageRank değerine sahip olabileceğidir. Sezgisel olarak, web’deki birçok yerden iyi alıntı yapılan sayfalara bakmaya değer. Ayrıca, Yahoo! anasayfa da genellikle bakmaya değer. Bir sayfanın kalitesi yüksek değilse veya bozuk bir bağlantıysa, Yahoo’nun ana sayfasının bu sayfaya link vermemesi olasıdır. PageRank, bu davaları ve aralarındaki her şeyi, ağın bağlantı yapısını tekrarlayan ağırlıkları ilerleterek ele alır.
2.2 Bağlantı Metni
Linklerin metni arama motorumuzda özel bir şekilde ele alınır. Çoğu arama motoru, bir bağlantının metnini, bağlantının bulunduğu sayfa ile ilişkilendirir. Ayrıca, bağlantıyı işaret ettiği sayfa ile ilişkilendiririz. Bunun birkaç avantajı var. İlk olarak, çapalar genellikle web sayfalarının kendisinden daha doğru web tanımları sağlar. İkinci olarak, görüntüler, programlar ve veritabanları gibi metin tabanlı bir arama motoru tarafından endekslenemeyen belgeler için bağlantı olabilir. Bu, gerçekten taranmamış web sayfalarını döndürmeyi mümkün kılar. Taranmamış sayfaların, kullanıcıya iade edilmeden önce geçerliliği kontrol edilmediklerinden sorunlara yol açabileceğini unutmayın. Bu durumda, arama motoru daha önce hiç bulunmayan ancak köprüleri işaret eden bir sayfa bile verebilir.
Bağlantı metnini, kastettiği sayfaya yayma fikri, World Wide Web Worm [ McBryan 94 ] içinde, özellikle de metin dışı bilgilerin aranmasına yardımcı olduğu ve daha az indirilen belge içeren arama kapsamını genişlettiği için uygulandı . Bağlantı yayını çoğunlukla kullanıyoruz çünkü bağlantı metni daha iyi kalitede sonuçlar almanıza yardımcı olabilir. Bağlantı metnini verimli bir şekilde kullanmak, işlenmesi gereken büyük miktarda veri nedeniyle teknik olarak zordur. Şu anki 24 milyon sayfalık taramamızda, endekslediğimiz 259 milyondan fazla çapa vardı.
2.3 Diğer Özellikler
PageRank’in yanı sıra bağlantı metni kullanımının yanı sıra, Google’ın başka birçok özelliği daha vardır. Birincisi, tüm isabetler için konum bilgisine sahiptir ve bu nedenle aramada yakınlığı yoğun şekilde kullanır. İkincisi, Google, kelimelerin yazı tipi boyutu gibi bazı görsel sunum ayrıntılarını izler. Daha büyük veya daha kalın yazı tipindeki sözcükler, diğer sözcüklerden daha fazla ağırlıklıdır. Üçüncüsü, tam ham sayfaların HTML’si bir depoda mevcuttur.
3. İlgili Çalışma
İnternette yapılan araştırma araştırması kısa ve özlü bir geçmişe sahiptir. World Wide Web Worm (WWWW) [McBryan 94] ilk web arama motorlarından biriydi. Daha sonraları birçoğu halka açık şirketlerden olan diğer birçok akademik arama motoru izledi. Web’in büyümesi ve arama motorlarının önemi ile karşılaştırıldığında, son arama motorları hakkında değerli birkaç doküman bulunmaktadır [ Pinkerton 94 ]. Michael Mauldin’e göre (baş bilim adamı, Lycos Inc) [Mauldin]“çeşitli servisler (Lycos dahil) bu veritabanlarının ayrıntılarını yakından koruyor”. Ancak, arama motorlarının belirli özellikleri üzerinde oldukça fazla çalışma yapılmıştır. Özellikle iyi temsil edilenler, mevcut ticari arama motorlarının sonuçlarını sonradan işleyerek veya küçük ölçekli “bireyselleştirilmiş” arama motorları üreterek sonuç alabilen çalışmadır. Son olarak, bilgi toplama sistemleri, özellikle de iyi kontrol edilen koleksiyonlar hakkında birçok araştırma yapılmıştır. Sonraki iki bölümde, bu araştırmanın web’de daha iyi çalışması için genişletilmesi gereken bazı alanları tartışıyoruz.
3.1 Bilgi Edinme
Bilgi edinme sistemlerinde çalışmak uzun yıllar öncesine dayanıyor ve iyi gelişmiştir [ Witten 94 ]. Bununla birlikte, bilgi edinme sistemleri üzerine yapılan araştırmaların çoğu, bilimsel bir makale veya ilgili bir konudaki haber öyküleri gibi iyi kontrol edilmiş küçük homojen koleksiyonlar üzerinedir. Nitekim, bilgi alma için temel kriter olan Metin Alma Konferansı [ TREC 96], kıyaslamaları için oldukça küçük, iyi kontrol edilen bir koleksiyon kullanıyor. “Çok Büyük Corpus” testi, 24 milyon web sayfasını taradığımız 147GB’a kıyasla sadece 20GB. TREC’de iyi çalışan şeyler genellikle web’de iyi sonuçlar vermez. Örneğin, standart vektör uzayı modeli, hem sorgunun hem de dokümanın kendi sözcük oluşumları tarafından tanımlanan vektörler olduğu göz önüne alındığında sorguyla en yakın yaklaşan dokümanı döndürmeye çalışır. Web’de, bu strateji genellikle sorgu ve birkaç kelime içeren çok kısa belgeler döndürür. Örneğin, büyük bir arama motorunun yalnızca “Bill Clinton Sucks” ve “Bill Clinton” sorgusunun resmini içeren bir sayfa döndürdüğünü gördük. Bazıları, web’de kullanıcıların istediklerini daha doğru bir şekilde belirtmeleri ve sorgularına daha fazla kelime eklemeleri gerektiğini savunuyor. Bu pozisyona şiddetle karşı çıkıyoruz. Bir kullanıcı “Bill Clinton” gibi bir sorgu yayınlarsa, bu konuda çok fazla miktarda yüksek kaliteli bilgi bulunduğundan makul sonuçlar almalıdır. Bunun gibi örnekler verildiğinde, standart bilgi alma çalışmasının web ile etkin bir şekilde başa çıkmak için genişletilmesi gerektiğine inanıyoruz.
3.2 Web ile İyi Kontrol Edilen Koleksiyonlar Arasındaki Farklar
Ağ tamamen kontrolsüz heterojen belgelerin geniş bir koleksiyonudur. Web üzerindeki dokümanlar, dokümanların içinde ve mevcut olabilecek harici meta bilgilerinde çok büyük farklılıklar gösterir. Örneğin, belgeler dillerinde (hem insan hem de programlama), kelime dağarcığını (e-posta adresleri, bağlantılar, posta kodları, telefon numaraları, ürün numaraları), tür veya biçimlerde (metin, HTML, PDF, resimler, sesler) ve hatta makine üretilebilir (günlük dosyaları veya bir veritabanından çıktılar). Öte yandan, dış meta bilgisini bir döküman hakkında çıkarılabilecek fakat içinde bulunmayan bilgiler olarak tanımlarız. Dış meta bilgi örnekleri, kaynağın itibarı, güncelleme sıklığı, kalite, popülerlik veya kullanım ve alıntılar gibi şeyleri içerir. Olası harici meta bilgi kaynakları sadece çeşitlilik göstermekle kalmaz, ölçülenler de büyüklük derecelerine göre değişir. Örneğin, her gün şu anda milyonlarca sayfa görünümü alan Yahoo gibi her on yılda bir görüş alabilecek karanlık ve tarihi bir makale ile kullanım bilgilerini ana sayfadan karşılaştırın. Açıkçası, bu iki maddeye bir arama motoru tarafından çok farklı davranılmalı.
Web ile geleneksel olarak iyi kontrol edilen koleksiyonlar arasındaki bir diğer büyük fark, insanların web’de neler yapabilecekleri üzerinde neredeyse hiçbir kontrol bulunmamasıdır. Arama motorlarının trafiği yönlendirmek için muazzam etkisi olan bir şey yayınlamak için bu esnekliği bir araya getirin ve arama motorlarını kasıtlı olarak kâr etmek isteyen şirketler ciddi bir sorun haline geldi. Geleneksel kapalı bilgi erişim sistemlerinde ele alınmayan bu sorun. Ayrıca, meta veri çabalarının büyük ölçüde web arama motorlarında başarısız olduğunu not etmek ilginçtir, çünkü sayfadaki kullanıcıya doğrudan temsil edilmeyen herhangi bir metin arama motorlarını manipüle etmek için kötüye kullanılır. Arama motorlarını kâr amaçlı kullanma konusunda uzmanlaşmış çok sayıda şirket bile var.
4. Sistem Anatomisi
Öncelikle, mimarlık hakkında yüksek düzeyde bir tartışma yapacağız. Daha sonra, önemli veri yapılarının bazı ayrıntılı açıklamaları vardır. Son olarak, ana uygulamalar: tarama, indeksleme ve arama derinlemesine incelenecektir.
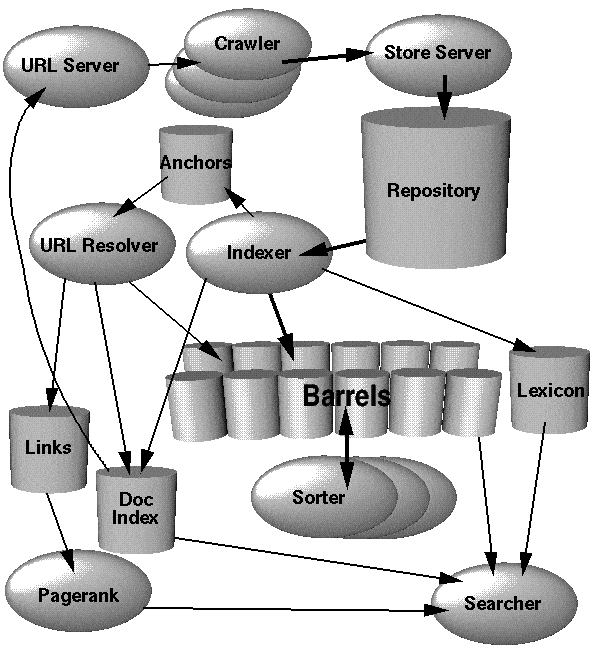
4.1 Google Mimarisine Genel Bakış
Bu bölümde, tüm sistemin Şekil 1’de gösterildiği gibi nasıl çalıştığı hakkında üst düzey bir genel bakış sunacağız. Diğer bölümler, bu bölümde bahsedilmeyen uygulamaları ve veri yapılarını tartışacaktır. Google’ın çoğu verimlilik için C veya C ++ dilinde yazılmıştır ve Solaris veya Linux’ta çalışabilir.
Google’da web taraması (web sayfalarının indirilmesi) birkaç dağıtık tarayıcı tarafından yapılır. Tarayıcılara alınacak URL listelerini gönderen bir URL sunucusu vardır. Alınan web sayfaları daha sonra mağaza sunucusuna gönderilir. Depo sunucusu daha sonra web sayfalarını bir havuza sıkıştırır ve saklar. Her web sayfasının, web sayfasından yeni bir URL ayrıştırıldığında atanan, docID adlı bir kimlik numarası vardır. İndeksleme fonksiyonu, indeksleyici ve sıralayıcı tarafından gerçekleştirilir. İndeksleyici birkaç fonksiyon gerçekleştirir. Depoyu okur, belgeleri sıkıştırır ve ayrıştırır. Her belge, isabet adı verilen bir takım kelime oluşumuna dönüştürülür. İsabetler kelimeyi, belgedeki pozisyonu, font büyüklüğünün bir yaklaştırmasını ve büyük / küçük harfleri kaydeder. İndeksleyici bu isabetleri bir “varil” kümesine dağıtır, kısmen sıralanmış bir ileri indeks yaratma. Dizin oluşturucu başka bir önemli işlevi yerine getirir. Her web sayfasındaki tüm bağlantıları ayrıştırır ve onlar hakkında önemli bilgileri bir bağlantı dosyasında saklar. Bu dosya, her bir bağlantının nereden gelip nereye geldiğini ve bağlantının metnini belirlemek için yeterli bilgi içerir.
URLresolver bağlantı dosyasını okur ve göreli URL’leri mutlak URL’lere ve ardından docID’lere dönüştürür. Çapa metnini, çapanın işaret ettiği docID ile ilişkilendirilmiş ileri dizine koyar. Ayrıca, docID çiftleri olan bir bağlantı veritabanı oluşturur. Links veritabanı tüm belgeler için PageRanks hesaplamak için kullanılır.
Sıralayıcı, docID’ye göre sıralanmış varilleri alır (bu bir basitleştirmedir, bkz. Bölüm 4.2.5 ) ve bunları ters çevrilmiş endeksi oluşturmak için wordID’ye göre yerleştirir. Bu, bu işlem için çok az geçici alana ihtiyaç duyulacak şekilde yapılır. Sıralayıcı ayrıca, tersine çevrilmiş indeks içine bir wordID listesi ve ofset oluşturur. DumpLexicon adlı bir program bu listeyi indeksleyici tarafından üretilen sözlüğü ile birlikte alır ve araştırmacı tarafından kullanılacak yeni bir sözlüğü oluşturur. Araştırmacı, bir web sunucusu tarafından çalıştırılır ve sorguları yanıtlamak için DumpLexicon tarafından oluşturulan sözlüğü ters çevrilmiş dizin ve PageRanks ile birlikte kullanır.
4.2 Başlıca Veri Yapıları
Google’ın veri yapıları, büyük bir belge koleksiyonunun taranabilmesi, dizine eklenmesi ve düşük maliyetle aranması için optimize edilmiştir. Her ne kadar CPU ve toplu giriş çıkış oranları yıllar içinde çarpıcı bir şekilde artmış olsa da, bir disk arayışının tamamlanması için hala 10 ms gerekiyor. Google, mümkün olduğunda diskin aranmasını önlemek için tasarlanmıştır ve bunun veri yapılarının tasarımı üzerinde önemli bir etkisi olmuştur.
4.2.1 Büyük Dosyalar
BigFiles, çoklu dosya sistemlerini kapsayan sanal dosyalardır ve 64 bit tamsayılarla adreslenebilir. Birden fazla dosya sistemi arasındaki tahsis otomatik olarak yapılır. BigFiles paketi ayrıca, işletim sistemlerimiz ihtiyaçlarımız için yeterli olmadığından, dosya tanımlayıcıların tahsisini ve dağıtılmasını da yönetir. BigFiles ayrıca basit sıkıştırma seçeneklerini de destekliyor.
4.2.2 Havuz

Depo her web sayfasının tam HTML’sini içerir. Her sayfa zlib kullanılarak sıkıştırılmıştır (bkz. RFC1950 ). Sıkıştırma tekniğinin seçimi, hız ve sıkıştırma oranı arasındaki farktır. Zlib’in hızını bzip’in sunduğu sıkıştırma konusunda önemli bir gelişme olarak seçtik . Bzip’in sıkıştırma oranı, zlib’in 3 ila 1 sıkıştırmasına kıyasla, depoda yaklaşık 4 ila 1 idi. Depoda, belgeler birbiri ardına depolanır ve Şekil 2’de görüldüğü gibi docID, uzunluk ve URL ile eklenmiştir. Depo, erişmek için başka hiçbir veri yapısının kullanılmasını gerektirmez. Bu, veri tutarlılığına yardımcı olur ve gelişimi çok kolaylaştırır; tüm veri yapılarını sadece havuzdan ve tarayıcı hatalarını listeleyen bir dosyadan yeniden oluşturabiliriz.
4.2.3 Belge Dizini
Belge dizini, her belge hakkında bilgi tutar. Bu, docID tarafından sipariş edilen sabit genişlikte bir ISAM (Dizin ardışık erişim modu) dizinidir. Her girişte saklanan bilgiler geçerli belge durumunu, depodaki işaretçiyi, belge sağlama toplamını ve çeşitli istatistikleri içerir. Doküman tarandıysa, URL’sini ve başlığını içeren docinfo adlı değişken genişlikli dosyaya bir işaretçi de içerir. Aksi halde, işaretçi yalnızca URL’yi içeren URL listesine işaret eder. Bu tasarım kararı, makul derecede kompakt bir veri yapısına sahip olma arzusu ve bir arama sırasında tek bir diskte bir kayıt alma yeteneği tarafından yönlendirildi.
Ek olarak, URL’leri docID’lere dönüştürmek için kullanılan bir dosya var. URL’leri karşılık gelen docID’leriyle birlikte gösteren bir listedir ve sağlama toplamına göre sıralanır. Belirli bir URL’nin docID’sini bulmak için, URL’nin sağlama toplamı hesaplanır ve sağlama toplamı dosyasında docID’sini bulmak için ikili arama yapılır. URL’ler, bu dosyayla birleştirme yapılarak toplu olarak docID’lere dönüştürülebilir. Bu, URLresolver’ın URL’leri docID’lere dönüştürmek için kullandığı tekniktir. Bu toplu güncelleme modu çok önemlidir, çünkü aksi takdirde bir diskin 322 milyon link veri setimiz için bir aydan uzun süreceğini varsayarak her bağlantı için bir arama yapmalıyız.
4.2.4 Sözlük
Sözlüğün birkaç farklı formu vardır. Önceki sistemlerden önemli bir değişiklik sözlüğün makul bir fiyata belleğe sığabilmesidir. Mevcut uygulamada sözlüğün 256 MB ana belleğe sahip bir makinede bellekte kalmasını sağlayabiliriz. Şu anki sözlük 14 milyon kelime içeriyor (yine de bazı nadir kelimeler sözlüğe eklenmemiş). İki bölüme uygulanmıştır – kelimelerin bir listesi (bir araya getirilmiş ancak boşlar ile ayrılmış) ve bir karma tablo tablosu. Çeşitli fonksiyonlar için, kelimelerin listesi tam olarak açıklamak için bu yazının kapsamı dışında kalan bazı yardımcı bilgilere sahiptir.
4.2.5 Vuruş Listeleri
Bir isabet listesi, konum, yazı tipi ve büyük harf bilgileri dahil olmak üzere belirli bir belgedeki belirli bir kelimenin oluşum listesine karşılık gelir. Hit listeleri hem ileri hem de ters endekslerde kullanılan alanın çoğunu oluşturur. Bu nedenle, onları mümkün olduğu kadar verimli bir şekilde göstermek önemlidir. Kodlama konumu, yazı tipi ve büyük harf kullanımı için basit seçenekler – basit kodlama (tamsayıların üçlü), kompakt kodlama (elle optimize edilmiş bit tahsisi) ve Huffman kodlaması. Sonunda, basit kodlamadan çok daha az alan ve Huffman kodlamadan çok daha az bit manipülasyon gerektirdiğinden, elle optimize edilmiş bir kompakt kodlama seçtik. Vuruşların detayları Şekil 3’te gösterilmektedir.
Kompakt kodlamamız her hit için iki bayt kullanır. İki tür isabet vardır: süslü isabetler ve düz isabetler. Süslü isabetler, bir URL, başlık, bağlantı metni veya meta etiketinde gerçekleşen isabetleri içerir. Düz vuruşlar her şeyi içerir. Basit bir isabet, bir büyük harf, yazı tipi boyutu ve bir belgede 12 bit kelime konumu (4095’ten büyük olan tüm konumlar 4096 olarak etiketlenir). Yazı tipi boyutu, belgenin geri kalanına göre üç bit kullanılarak gösterilir (111, süslü bir vuruşu işaret eden bayrak olduğu için aslında 7 değer kullanılır). Süslü bir isabet, büyük harfli bir bit, font büyüklüğü, isabetli bir isabet olduğunu belirtmek için 7’ye, süslü isabet türünü kodlamak için 4 bit ve 8 bit pozisyondan oluşur. Ankraj isabetleri için, 8 bit pozisyon, ankraj için pozisyon için 4 bit ve ankrajın oluştuğu dokümanın bir hash için 4 bit olarak bölünür. Bu bize, belirli bir kelime için çok fazla çapa olmadığı sürece, arama yapmayı sınırlı ifade eder. Pozisyon ve docIDhash alanlarında daha iyi çözünürlük elde etmek için çapa isabetlerinin saklanma şeklini güncellemeyi umuyoruz. Belgenin geri kalanına göre font boyutunu kullanırız, çünkü arama yaparken, belgelerin biri daha büyük bir fontta olduğu için aynı belgeleri farklı şekilde sıralamak istemezsiniz.
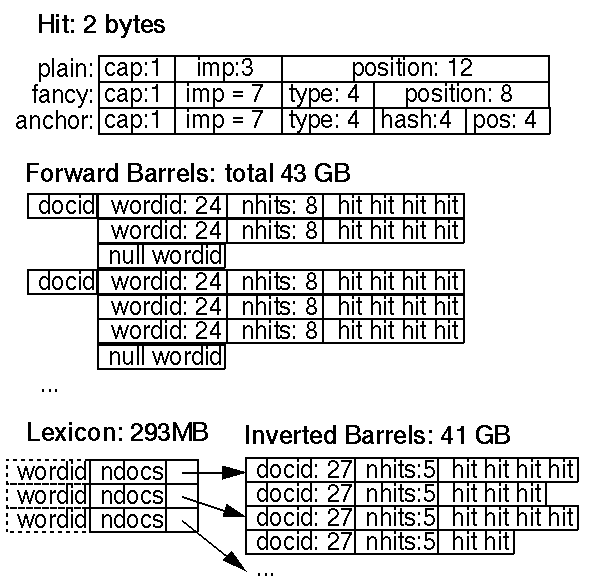
Bir isabet listesinin uzunluğu, isabetlerin kendisinden önce saklanır. Yer kazanmak için, isabet listesinin uzunluğu ileri dizindeki wordID ve ters dizindeki docID ile birleştirilir. Bu, sırasıyla 8 ve 5 bit ile sınırlar (8 bitin ID kelimesinden ödünç alınmasına izin veren bazı numaralar vardır). Uzunluk bu bitlere uyacağından daha uzunsa, bu bitlerde bir kaçış kodu kullanılır ve sonraki iki bayt gerçek uzunluğu içerir.
4.2.6 İleri Endeks Endeksi
İleri endeksi aslında zaten kısmen sıralanır. Birkaç varilde depolanır (64 kullandık). Her namlu bir dizi wordID içerir. Bir belge belirli bir varile düşen kelimeleri içeriyorsa, docID, varile kaydedilir ve ardından bu kelimelere karşılık gelen hit listeleri içeren bir wordID listesi bulunur. Bu şema, çoğaltılmış dokümanlar nedeniyle biraz daha fazla depolama gerektirir, ancak makul sayıda kova için fark çok azdır ve sıralayıcı tarafından yapılan son indeksleme aşamasında önemli zaman ve kodlama karmaşıklığı kazandırır. Ayrıca, gerçek kelime kimliklerini depolamak yerine, her bir sözcük kimliğini, sözcük kimliğindeki varile düşen minimum sözcük kimliğinden göreceli bir fark olarak depolarız. Böylece, kimliği kesilen varillerdeki sözcük kimliği için sadece 24 bit kullanabiliriz.
4.2.7 Ters İndeks
Ters çevrilmiş endeks, sıralayıcı tarafından işlenmeleri dışında, ileri endeks ile aynı varillerden oluşur. Her geçerli wordID için, sözlük sözlüğü wordID’nin içine düştüğü varile bir işaretçi içerir. Dokümanların doktora listesine karşılık gelen isabet listelerini gösterir. Bu doktor listesi, o kelimenin tüm cümle içindeki tüm cisimlerini temsil eder.
Önemli bir sorun, doktor kimliğinin doktor listesinde hangi sırayla görünmesi gerektiğidir. Basit bir çözüm, onları docID’ye göre sıralamaktır. Bu, birden fazla kelime sorgusu için farklı doktorların hızlı bir şekilde birleştirilmesine olanak sağlar. Diğer bir seçenek ise, onları her bir belgedeki kelimenin oluşum sıralamasına göre sıralamaktır. Bu, bir kelime sorgusuna cevap vermeyi önemsiz kılar ve birden çok kelime sorgusuna verilen cevapların başlangıç noktasına yakın olması ihtimalini arttırır. Ancak, birleştirmek çok daha zor. Ayrıca, sıralama fonksiyonunda yapılan bir değişikliğin endeksin yeniden oluşturulmasını gerektirmesi nedeniyle gelişimi daha da zorlaştırır. Bu seçenekler arasında bir uzlaşma seçtik, iki ters çevrilmiş varil takımı tutuldu – biri başlık ya da çapa isabetleri içeren isabet listeleri ve diğer isabet listeleri için diğer isabetler. Bu yoldan,
4.3 Web’i Tarama
Bir web tarayıcısını çalıştırmak zor bir iştir. Zor performans ve güvenilirlik sorunları var ve daha da önemlisi sosyal konular var. Tarama, yüzlerce web sunucusu ve sistemin kontrolünün ötesinde olan çeşitli ad sunucularıyla etkileşimi içerdiğinden en kırılgan uygulamadır.
Yüz milyonlarca web sayfasını ölçeklendirmek için Google’ın hızlı dağıtılmış bir tarama sistemi vardır. Tek bir URL sunucusu, çeşitli tarayıcılara yönelik URL listelerini sunar (genellikle yaklaşık 3 koştuk). Hem URLserver hem de tarayıcılar Python’da uygulanmaktadır. Her tarayıcı bir seferde yaklaşık 300 bağlantıyı açık tutar. Bu, web sayfalarını yeterince hızlı bir şekilde almak için gereklidir. En yüksek hızlarda, sistem dört tarayıcı kullanarak saniyede 100’den fazla web sayfasını tarayabilir. Bu veri saniyede yaklaşık 600 K tutarındadır. Büyük bir performans stresi DNS aramasıdır. Her tarayıcı kendi DNS önbelleğini korur, böylece her belgeyi taramadan önce bir DNS araması yapması gerekmez. Yüzlerce bağlantının her biri birkaç farklı durumda olabilir: DNS aramak, ana bilgisayara bağlanmak, istek göndermek ve yanıt almak. Bu faktörler, tarayıcıyı sistemin karmaşık bir bileşeni yapar. Olayları yönetmek için zaman uyumsuz IO ve sayfa getirmelerini durumdan duruma taşımak için bir dizi kuyruk kullanır.
Yarım milyondan fazla sunucuya bağlanan ve on milyonlarca günlük girişi oluşturan bir tarayıcı çalıştırmanın, makul miktarda e-posta ve telefon görüşmesi ürettiği ortaya çıktı. Sıradaki çok sayıda insan nedeniyle, her zaman bir tarayıcının ne olduğunu bilmeyenler vardır, çünkü ilk gördükleri kişi budur. Neredeyse her gün, “Vay, web sitemden çok fazla sayfaya baktınız. Nasıl beğendin?” Gibi bir e-posta alıyoruz. Robotların dışlanma protokolü hakkında bilgisi olmayan bazı insanlar da var.ve sayfalarının, “Bu sayfa telif hakkıyla korunuyor ve dizine eklenmemesi” şeklinde bir ifadeyle korunmaları gerektiğini ve bunun da web tarayıcılarının anlaması zor olduğunu söylemeye gerek yok. Ayrıca, büyük miktarda veri nedeniyle beklenmedik şeyler olacak. Örneğin, sistemimiz çevrimiçi bir oyun taramaya çalıştı. Bu, oyunlarının ortasında birçok çöp mesajla sonuçlandı! Anlaşılan bu sorunu çözmek için kolay bir problemdi. Ancak bu sorun, on milyonlarca sayfa indirene kadar ortaya çıkmamıştı. Web sayfalarındaki ve sunuculardaki büyük farklılıklar nedeniyle, bir tarayıcıyı İnternet’in büyük bir bölümünde çalıştırmadan test etmek neredeyse imkansızdır. Her zaman, web’in sadece bir sayfasında ortaya çıkabilen ve tarayıcının çökmesine veya daha da kötüye gitmesine neden olabilecek yüzlerce gizli sorun vardır. öngörülemeyen veya yanlış davranışa neden olur. İnternetin büyük bölümlerine erişen sistemlerin çok sağlam ve dikkatlice test edilecek şekilde tasarlanması gerekir. Tarayıcı gibi büyük karmaşık sistemler her zaman sorunlara neden olacağından, e-postayı okumaya ve bu sorunları ortaya çıktıkça çözmeye adanmış önemli kaynaklar olması gerekir.
4.4 Web’in Endekslenmesi
Ayrıştırma – Web’in tamamında çalışmak üzere tasarlanmış herhangi bir ayrıştırıcı, çok çeşitli olası hataları ele almalıdır. Bunlar, HTML etiketlerindeki yazım hatalarından bir etiketin ortasındaki kilobaytlık sıfırlara, ASCII olmayan karakterlere, yüzlerce derinliğe yerleştirilmiş HTML etiketlerine ve kimsenin eşit derecede yaratıcı olanları hayal etme zorunluluğunu ortaya çıkaran çok çeşitli hatalara kadar çeşitlilik gösterir. Maksimum hız için, bir CFG ayrıştırıcısı oluşturmak için YACC kullanmak yerine, kendi yığınına uyan bir sözcüksel analizör üretmek için esnek kullanıyoruz. Makul bir hızda çalışan ve çok sağlam olan bu ayrıştırıcıyı geliştirmek, oldukça fazla çalışma gerektirmiştir.
Dizin Varil içine Belgeler – Her belge ayrıştırılır sonra, varil sayıya kodlanmıştır. Her kelime, bir bellek içi karma tablo kullanılarak bir sözcük kimliğine dönüştürülür – sözlük. Sözlük hash tablosuna yeni eklenenler bir dosyaya kaydedilir. Kelimeler wordID’lere dönüştürüldükten sonra, geçerli belgedeki oluşumları isabet listelerine çevrilir ve ileri varillere yazılır. Endeksleme aşamasının paralelleştirilmesindeki ana zorluk, sözlüğün paylaşılması gerektiğidir. Sözlüğü paylaşmak yerine, 14 milyon kelimeye sabitlediğimiz, temel bir sözlüğün olmayan tüm ek kelimelerin kayıtlarını yazma yaklaşımını kullandık. Bu şekilde birden fazla dizinleyici paralel olarak çalışabilir ve daha sonra ek sözcüklerin küçük günlük dosyası bir son dizinleyici tarafından işlenebilir.
Sıralama – Tersine çevrilmiş endeksi oluşturmak için, sıralayıcı her bir ileri namluyu alır ve başlık ve çapa isabetleri için tam bir ters namlu ve tam metin ters namlu için bir ters namlu üretmek için bunu wordID’ye göre sıralar. Bu işlem bir seferde bir varil olur, bu nedenle çok az geçici depolama gerektirir. Ayrıca, aynı anda farklı kovaları işleyebilen çok sayıda sıralayıcı çalıştırarak sahip olduğumuz kadar makineyi kullanmak için sıralama aşamasını paralelleştiriyoruz. Variller ana belleğe sığmadığından, sıralayıcı onları wordID ve docID’ye dayanarak belleğe sığacak sepetler halinde alt bölümlere ayırır. Daha sonra, sıralayıcı her sepeti belleğe yükler, sıralar ve içeriğini kısa ters çevrilmiş fıçıya ve ters çevrilmiş fıçıya yazar.
4.5 Arama
Aramanın amacı, verimli bir şekilde kaliteli arama sonuçları sağlamaktır. Büyük ticari arama motorlarının birçoğunun verimlilik açısından büyük ilerleme kaydettiği görülmüştür. Bu nedenle, çözümlerimizin ticari birimler için biraz daha fazla çaba harcayabildiğine inanmamıza rağmen, araştırmamızda arama kalitesi üzerinde daha fazla durduk. Google sorgu değerlendirme işlemi Şekil 4’te gösterilmektedir.

Yanıt süresini sınırlandırmak için, belirli sayıda (şu anda 40.000) eşleşen belge bulunduğunda, arama yapan kişi otomatik olarak Şekil 4’te 8. adıma geçer. Bu, alt-optimal sonuçların geri döndürülmesinin mümkün olduğu anlamına gelir. Şu anda bu sorunu çözmek için başka yollar araştırıyoruz. Geçmişte, durumu iyileştirmiş gibi görünen isabetlerini PageRank’e göre sıraladık.
4.5.1 Sıralama Sistemi
Google, web belgeleri hakkında tipik arama motorlarından çok daha fazla bilgi tutar. Her hitlist konum, yazı tipi ve büyük harf bilgilerini içerir. Ek olarak, çapa metninden ve belgenin Sayfa Sırasından isabet alıyor. Tüm bu bilgileri bir sıralamada birleştirmek zordur. Sıralama işlevimizi, hiçbir faktörün çok fazla etkisi olmayacak şekilde tasarladık. İlk önce, en basit durumu düşünün – tek bir kelime sorgusu. Tek bir kelime sorgusu olan bir dokümanı sıralamak için Google, o dokümanın söz konusu kelime listesine bakar. Google, her bir isabetin, her biri kendi tür ağırlığına sahip olan birkaç farklı türden (başlık, bağlantı, URL, düz metin büyük yazı tipi, düz metin küçük yazı tipi …) olduğunu düşünür. Tip ağırlıkları, türe göre indekslenmiş bir vektör oluşturur. Google, isabet listesindeki her türün isabet sayısını sayar. Sonra her sayım bir sayım ağırlığına dönüştürülür. Sayım ağırlıkları ilk başta sayımlarla doğrusal olarak artar, ancak hızlı bir şekilde azalır, böylece belirli bir sayının fazlası yardımcı olmaz. Belge için bir IR puanı hesaplamak için sayım ağırlıkları vektörünün nokta ürününü tür ağırlıkları vektörüyle alırız. Son olarak, IR puanı, belgeye son bir sıra vermek için PageRank ile birleştirilir.
Çok kelimeli bir arama için durum daha karmaşıktır. Şimdi bir kerede birden fazla isabet listesinin taranması gerekir, böylece bir belgede birbirine yakın olarak vurulan isabetler, birbirinden çok fazla vurulan isabetten daha fazladır. Birden fazla isabet listesinden isabetler eşleştirilir, böylece yakındaki isabetler birlikte eşleşir. Her eşleşme kümesi için bir yakınlık hesaplanır. Yakınlık, isabetlerin belgedeki (veya çapa) ne kadar uzakta olduğuna dayanır ancak bir cümle eşleşmesinden “yakın bile değil” arasında değişen 10 farklı değerde “kutu” olarak sınıflandırılır. Sayımlar yalnızca her isabet türü için değil, her bir tür ve yakınlık için de hesaplanır. Her tip ve yakınlık çifti bir tür prox ağırlığına sahiptir. Sayımlar sayım ağırlıklarına dönüştürülür ve bir IR puanını hesaplamak için sayım ağırlıkları ve tip-proks ağırlıkları nokta çarpımları alınır. Bu sayılar ve matrislerin tümü, özel bir hata ayıklama modu kullanılarak arama sonuçlarıyla görüntülenebilir. Bu ekranlar sıralama sistemini geliştirmede çok yardımcı oldular.
4.5.2 Geribildirim
Sıralama işlevi, tür ağırlıkları ve tür-prox ağırlıkları gibi birçok parametreye sahiptir. Bu parametreler için doğru değerleri bulmak siyah sanatta bir şeydir. Bunu yapmak için, arama motorunda bir kullanıcı geri bildirim mekanizmasına sahibiz. Güvenilir bir kullanıcı isteğe bağlı olarak döndürülen tüm sonuçları değerlendirebilir. Bu geri bildirim kaydedildi. Sonra sıralama işlevini değiştirdiğimizde, bu değişikliğin sıralanan tüm aramalar üzerindeki etkisini görebiliriz. Mükemmel olmaktan uzak olmasına rağmen, bu bize sıralama fonksiyonundaki bir değişikliğin arama sonuçlarını nasıl etkilediği hakkında biraz fikir verir.
5. Sonuç ve Performans

Bir arama motorunun en önemli ölçüsü, arama sonuçlarının kalitesidir. Tam bir kullanıcı değerlendirmesi bu yazının kapsamı dışında kalsa da, Google ile ilgili edindiğimiz deneyimler, çoğu arama için büyük ticari arama motorlarından daha iyi sonuçlar verdiğini göstermiştir. PageRank’in, bağlantı metninin ve yakınlığın kullanımını gösteren bir örnek olarak, Şekil 4, Google’ın “fatura kliniği” ile ilgili arama sonuçlarını göstermektedir. Bu sonuçlar, Google’ın bazı özelliklerini gösterir. Sonuçlar sunucu tarafından kümelenmiştir. Bu, sonuç kümeleri arasında gezinirken önemli ölçüde yardımcı olur. Bir sonuç, whitehouse.gov alanından alınmıştır; bu, böyle bir aramadan makul bir şekilde ne beklenebileceğini gösterir. Şu anda, çoğu büyük ticari arama motoru, whitehouse.gov’dan çok daha düşük bir sonuç vermedi. İlk sonuç için başlık bulunmadığına dikkat edin. Bunun nedeni sürünmemiş olmasıdır. Bunun yerine, Google bunun sorguya iyi bir cevap olduğunu belirlemek için bağlantı metnini kullandı. Benzer şekilde, beşinci sonuç, elbette taranamayan bir e-posta adresidir. Ayrıca metin çapa bir sonucudur.
Sonuçların tümü oldukça yüksek kaliteli sayfalardır ve son kontrolde hiçbiri bağlantıların kopuk olmasına neden olmamıştır. Bu büyük ölçüde, hepsinin de yüksek PageRank’e sahip olmaları. PageRanks, çubuk grafiklerle birlikte kırmızı olan yüzdelerdir. Son olarak, Clinton’dan başka bir Bill hakkında veya Bill’den başka bir Clinton hakkında sonuç yoktur. Bunun nedeni, kelime olaylarının yakınlığına büyük önem vermemizdir. Elbette, bir arama motorunun kalitesinin gerçek bir testi, burada geniş bir kullanıcı çalışmasını veya sonuç analizini içerecektir. Bunun yerine, okuyucuyu http://google.stanford.edu adresinde Google’ı kendileri için denemeye davet ediyoruz .
5.1 Depolama Gereksinimleri
Google, arama kalitesinin yanı sıra, maliyeti arttıkça Web’in boyutuna da etkili bir şekilde ölçeklendirmek için tasarlanmıştır. Bunun bir yönü, depolamayı verimli kullanmaktır. Tablo 1, Google’ın bazı istatistiklerinden ve depolama gereksinimlerinden bir dökümünü içermektedir. Sıkıştırma nedeniyle, depodaki toplam boyut yaklaşık 53 GB’dir, depoladığı toplam verilerin üçte birinden fazlası. Mevcut disk fiyatlarında bu, depoyu nispeten ucuz bir kullanışlı veri kaynağı yapar. Daha da önemlisi, arama motoru tarafından kullanılan tüm verilerin toplamı, yaklaşık 55 GB olan karşılaştırılabilir bir depolama alanı gerektirir. Ayrıca, çoğu sorgu sadece kısa bir ters indeks kullanılarak cevaplandırılabilir. Belge Dizininin daha iyi kodlanması ve sıkıştırılmasıyla, yüksek kaliteli bir web arama motoru 7GB’lık yeni bir PC sürücüsüne sığabilir.
Depolama İstatistikleri
Alınan Sayfaların Toplam Boyutu 147,8 GB
Sıkıştırılmış Havuz 53,5 GB
Kısa Ters İndeks 4,1 GB
Tam Ters İndeks 37,2 GB
sözlük 293 MB
Geçici Bağlantı Verileri
(toplamda değil) 6,6 GB
Belge Dizini Dahil
Değişken Genişlik Verileri 9,7 GB
Bağlantı Veritabanı 3,9 GB
Depo Yok Toplam 55,2 GB
Havuzlu Toplam 108,7 GB
Web Sayfası İstatistikleri
Alınan Web Sayfalarının Sayısı 24 milyon
Görülen URL’lerin Sayısı 76,5 milyon
E-posta Adresi Sayısı 1,7 milyon
404’ün sayısı 1.6 milyon
Tablo 1. İstatistikler
5.2 Sistem Performansı
Bir arama motorunun verimli bir şekilde taranması ve dizine eklenmesi önemlidir. Bu yolla bilgiler güncel tutulabilir ve sistemdeki büyük değişiklikler nispeten hızlı bir şekilde test edilebilir. Google için ana işlemler Tarama, Dizine Alma ve Sıralama. Disklerin dolması, ad sunucularının çökmesi veya sistemi durduran diğer birçok sorun nedeniyle taramanın ne kadar sürdüğünü ölçmek zordur. Toplamda 26 milyon sayfanın indirilmesi yaklaşık 9 gün sürdü (hatalar dahil). Bununla birlikte, sistem sorunsuz bir şekilde çalıştığında, son 11 milyon sayfayı yalnızca 63 saatte indirerek, ortalama olarak günde 4 milyon sayfa veya saniyede 48,5 sayfa yükleyerek çok daha hızlı çalıştı. İndeksleyiciyi ve tarayıcıyı eşzamanlı olarak çalıştırdık. Dizinleyici, tarayıcılardan daha hızlı çalıştı. Bu, büyük ölçüde, indeksleyiciyi optimize etmek için sadece bir darboğaz olamayacak kadar zaman harcadığımız için. Bu optimizasyonlar, belge dizininde toplu güncellemeler ve kritik veri yapılarının yerel diskteki yerleşimini içeriyordu. İndeksleyici saniyede yaklaşık 54 sayfadır. Sıralayıcılar tamamen paralel olarak çalıştırılabilir; Dört makine kullanarak, tüm sıralama işlemi yaklaşık 24 saat sürer.
5.3 Arama Performansı
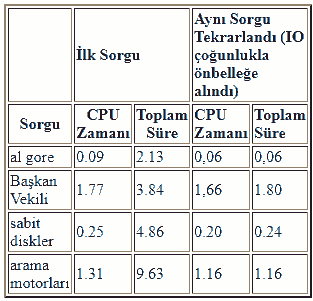
Arama performansını geliştirmek, bu noktaya kadar araştırmamızın odak noktası değildi. Google’ın şu anki sürümü çoğu sorguyu 1 ile 10 saniye arasında yanıtlamaktadır. Bu süre çoğunlukla NFS üzerindeki disk IO tarafından yönetilir (çünkü diskler birkaç makineye yayılır). Ayrıca, Google’ın sorgu önbelleğe alma, genel terimlerdeki alt dizinler ve diğer genel optimizasyonlar gibi optimizasyonları yoktur. Dağıtım ve donanım, yazılım ve algoritmik gelişmelerle Google’ı önemli ölçüde hızlandırmak istiyoruz. Hedefimiz saniyede birkaç yüz sorguyu ele almak. Tablo 2’de Google’ın geçerli sürümünden bazı örnek sorgu süreleri vardır. Önbelleklenmiş IO’dan kaynaklanan hızları göstermek için tekrarlanırlar.
6. Sonuçlar
Google, ölçeklenebilir bir arama motoru olacak şekilde tasarlanmıştır. Birincil hedef, hızla büyüyen bir World Wide Web üzerinden yüksek kaliteli arama sonuçları sağlamaktır. Google, sayfa sıralamasını, bağlantı metnini ve yakınlık bilgilerini içeren arama kalitesini artırmak için birkaç teknik kullanır. Ayrıca, Google web sayfalarını toplamak, dizine eklemek ve üzerlerinde arama sorguları yapmak için eksiksiz bir mimaridir.
6.1 Gelecekteki Çalışma
Büyük ölçekli bir web arama motoru karmaşık bir sistemdir ve yapılması gereken çok şey var. Hemen hedefimiz, arama verimliliğini artırmak ve yaklaşık 100 milyon web sayfasına ölçeklendirmektir. Verimlilikteki bazı basit iyileştirmeler arasında sorgu önbelleğe alma, akıllı disk ayırma ve alt dizinler sayılabilir. Çok araştırma gerektiren bir diğer alan güncellemeler. Hangi eski web sayfalarının taranması ve hangi yeni sayfaların taranması gerektiğine karar vermek için akıllı algoritmalarımız olmalıdır. Bu amaca yönelik çalışmalar [ Cho 98 ] ‘de yapılmıştır.]. Gelecek vaad eden bir araştırma alanı, talep odaklı olduklarından arama veritabanları oluşturmak için vekil önbellekleri kullanmak. Boole operatörleri, olumsuzlama ve kaynak bulma gibi ticari arama motorları tarafından desteklenen basit özellikleri eklemeyi planlıyoruz. Ancak, alaka düzeyi geri bildirimi ve kümeleme gibi diğer özellikler henüz keşfedilmeye başlamıştır (Google şu anda basit bir ana bilgisayar adı tabanlı kümelemeyi desteklemektedir). Ayrıca kullanıcı bağlamını (kullanıcının konumu gibi) ve sonuç özetlemesini desteklemeyi planlıyoruz. Ayrıca, link yapısı ve link metni kullanımını genişletmek için çalışıyoruz. Basit deneyler, bir kullanıcının ana sayfasının veya yer imlerinin ağırlığını artırarak PageRank’in kişiselleştirilebileceğini gösterir. Link metnine gelince, link metnine ek olarak metin çevreleyen linkleri kullanmayı deniyoruz. Bir Web arama motoru, araştırma fikirleri için çok zengin bir ortamdır. Burada listelenecek çok fazla şey var, bu yüzden bu Gelecek Çalışması bölümünün yakın gelecekte daha kısa olmasını beklemiyoruz.
6.2 Yüksek Kaliteli Arama
Günümüzde web arama motorlarının kullanıcılarının karşılaştığı en büyük sorun, geri aldıkları sonuçların kalitesidir. Sonuçlar genellikle eğlenceli ve kullanıcıların ufkunu genişletirken, çoğu zaman sinir bozucu oluyor ve değerli zaman tüketiyorlar. Örneğin, en popüler ticari arama motorlarından birinde “Bill Clinton” aramasının en iyi sonucu, 14 Nisan 1997 tarihli Bill Clinton Şakasıydı.. Google, web hızla büyümeye devam ettikçe bilgileri kolayca bulabilmesi için daha kaliteli arama sağlamak üzere tasarlanmıştır. Bunu başarmak için Google, bağlantı yapısı ve bağlantı (çapa) metninden oluşan köprü metni bilgisini yoğun şekilde kullanır. Google ayrıca yakınlık ve yazı tipi bilgilerini kullanır. Bir arama motorunun değerlendirilmesi zor olsa da, Google’ın mevcut ticari arama motorlarından daha kaliteli arama sonuçları döndürdüğünü tespit ettik. Bağlantı yapısının PageRank aracılığıyla analizi, Google’ın web sayfalarının kalitesini değerlendirmesini sağlar. Bağlantı metninin, arama motorunun alakalı (ve bir dereceye kadar yüksek kalitede) sonuç almasına yardımcı olmak için neyi işaret ettiğini gösteren bir açıklama olarak kullanılması. Son olarak, yakınlık bilgilerinin kullanılması, birçok sorgu için alaka düzeyini büyük ölçüde artırmaya yardımcı olur.
6.3 Ölçeklenebilir Mimari
Arama kalitesinin yanı sıra, Google ölçeklendirmek için tasarlanmıştır. Hem mekanda hem de zamanda etkili olması gerekir ve Web’in tamamında iş yaparken sürekli faktörler çok önemlidir. Google’ı uygularken CPU’da, bellek erişiminde, bellek kapasitesinde, disk aramalarında, disk çıkışlarında, disk kapasitesinde ve ağ IO’sundaki darboğazları gördük. Google, çeşitli işlemler sırasında bu darboğazların üstesinden gelmek için gelişti. Google’ın ana veri yapıları, kullanılabilir depolama alanını verimli bir şekilde kullanır. Ayrıca, tarama, indeksleme ve sıralama işlemleri bir haftadan kısa bir sürede, 24 milyon sayfadan oluşan webin önemli bir bölümünün indeksini oluşturabilecek kadar verimlidir. Bir aydan daha az bir sürede 100 milyon sayfalık bir dizin oluşturmayı umuyoruz.
6.4 Bir Araştırma Aracı
Yüksek kaliteli bir arama motoru olmasının yanı sıra, Google bir araştırma aracıdır. Google’ın topladığı veriler, konferanslara gönderilen pek çok makaleyle ve daha pek çok şeyle sonuçlandı. [ Abiteboul 97 ] gibi son zamanlarda yapılan araştırmalar , Web’in yerel olarak mevcut olması gerekmeden yanıtlanabilecek Web ile ilgili sorgularda bazı sınırlamalar olduğunu göstermiştir. Bu, Google’ın (veya benzer bir sistemin) yalnızca değerli bir araştırma aracı değil, aynı zamanda çok çeşitli uygulamalar için gerekli olduğu anlamına gelir. Google’ın tüm dünyada araştırmacılar ve araştırmacılar için bir kaynak olacağını ve gelecek nesil arama motoru teknolojisini tetikleyeceğini umuyoruz.
7. Teşekkürler
Scott Hassan ve Alan Steremberg Google’ın gelişimi için kritik öneme sahipti. Yetenekli katkıları yeri doldurulamaz ve yazarlar onlara çok teşekkür borçludur. Ayrıca Hector Garcia-Molina, Rajeev Motwani, Jeff Ullman ve Terry Winograd’a ve tüm WebBase grubuna destekleri ve içgörüsel tartışmaları için teşekkür ediyoruz. Son olarak, donör donörlerimizin IBM, Intel ve Sun ile fon sağlayıcılarımızın cömert desteğini kabul etmek istiyoruz. Burada açıklanan araştırma, IRI-9411306 İşbirliği Anlaşması uyarınca Ulusal Bilim Vakfı tarafından desteklenen Stanford Entegre Dijital Kütüphane Projesinin bir parçası olarak gerçekleştirildi. Bu işbirliği anlaşması için fon, DARPA ve NASA, ve Interval Research ve Stanford Digital Libraries Projesinin endüstriyel ortakları tarafından da sağlanmaktadır.
Referanslar
Web’in En İyisi 1994 – Gezgin http://botw.org/1994/awards/navigators.html
Bill Clinton Günün Şakası: 14 Nisan 1997. http://www.io.com/~cjburke/clinton/970414.html.
Bzip2 Ana Sayfası http://www.muraroa.demon.co.uk/
Google Arama Motoru http://google.stanford.edu/
Hasat http://harvest.transarc.com/
Mauldin, Michael L. Lycos İnternet Arama Hizmetinde Tasarım Seçenekleri, IEEE Uzmanı Röportajı http://www.computer.org/pubs/expert/1997/trends/x1008/mauldin.htm
Sürücünün Dikkatine Cep Telefonunun Kullanımının Etkisi http://www.webfirst.com/aaa/text/cell/cell0toc.htm
Arama Motoru İzlemesi http://www.searchenginewatch.com/
RFC 1950 (zlib) ftp://ftp.uu.net/graphics/png/documents/zlib/zdoc-index.html
Robotlar Hariç Tutma Protokolü: http://info.webcrawler.com/mak/projects/robots/exclusion.htm
Web Büyüme Özeti: http://www.mit.edu/people/mkgray/net/web-growth-summary.html
Yahoo! http://www.yahoo.com/
[Abiteboul 97] Serge Abiteboul ve Victor Vianu, İnternette Sorgu ve Hesaplama . Uluslararası Veri Tabanı Teorisi Konferansı Bildirileri. Delphi, Yunanistan 1997.
[Bagdikian 97] Ben H. Bagdikian. Medya Tekeli . 5. Baskı. Yayınevi: Beacon, ISBN: 0807061557
[Chakrabarti 98] S. Chakrabarti, B.Dom, D.Gibson, J.Kleinberg, P. Raghavan ve S. Rajagopalan. Köprü Yapısını ve İlişkili Metni Çözümleyerek Otomatik Kaynak Derlemesi. Yedinci Uluslararası Web Konferansı (WWW 98). Brisbane, Avustralya, 14-18 Nisan 1998.
[Cho 98] Junghoo Cho, Hector Garcia-Molina, Lawrence Sayfa. URL Siparişinde Verimli Tarama. Yedinci Uluslararası Web Konferansı (WWW 98). Brisbane, Avustralya, 14-18 Nisan 1998.
[Gravano 94] Luis Gravano, Hector Garcia-Molina ve A. Tomasic. Metin Veritabanı Keşfi Sorunu İçin GlOSS’un Etkinliği. Proc. 1994 ACM SIGMOD Uluslararası Veri Yönetimi Konferansı, 1994.
[Kleinberg 98] Jon Kleinberg, Köprülü Bir Ortamdaki Yetkili Kaynaklar , Proc. ACM-SIAM Kesikli Algoritmalar Sempozyumu, 1998.
[Marchiori 97] Massimo Marchiori. Web’deki Doğru Bilgi Arayışı: Hiper Arama Motorları. Altıncı Uluslararası WWW Konferansı (WWW 97). Santa Clara, ABD, 7-11 Nisan 1997.
[McBryan 94] Oliver A. McBryan. GENVL ve WWWW: Web’i Düzleştirmek için Araçlar Dünya Çapında Ağ Üzerine İlk Uluslararası Konferans. CERN, Cenevre (İsviçre), 25-26-27 Mayıs 1994. http://www.cs.colorado.edu/home/mcbryan/mypapers/www94.ps
[Sayfa 98] Lawrence Sayfa, Sergey Brin, Rajeev Motwani, Terry Winograd. PageRank Alıntı Sıralaması: Siparişi Web’e Getirmek. Yazma devam ediyor. http://google.stanford.edu/~backrub/pageranksub.ps
[Pinkerton 94] Brian Pinkerton, İnsanların Ne İstediğini Bulma: WebCrawler ile Deneyimler. İkinci Uluslararası WWW Konferansı Chicago, ABD, 17-20 Ekim 1994. http://info.webcrawler.com/bp/WWW94.html
[Spertus 97] Ellen Spertus. ParaSite: Web’de Yapısal Bilgi Madenciliği. Altıncı Uluslararası WWW Konferansı (WWW 97). Santa Clara, ABD, 7-11 Nisan 1997.
[TREC 96] Beşinci Metin Yazışma Konferansı Bildirileri (TREC-5). Gaithersburg, Maryland, 20-22 Kasım 1996. Yayınevi: Ticaret Bölümü, Ulusal Standartlar ve Teknoloji Enstitüsü. Editörler: DK Harman ve EM Voorhees. Tam metin: http://trec.nist.gov/
[Witten 94] Ian H Witten, Alistair Moffat ve Timothy C. Bell. Gigabaytları Yönetme: Belgeleri ve Görüntüleri Sıkıştırma ve Dizine Alma. New York: Van Nostrand Reinhold, 1994.
[Weiss 96] Ron Weiss, Bienvenido Velez, Mark A. Sheldon, Chanathip Manprempre, Peter Szilagyi, Andrzej Duda ve David K. Gifford. HyPursuit: Content-Link Hypertext Clustering’i Kullanan Hiyerarşik Bir Ağ Arama Motoru. Hypertext Üzerine 7. ACM Konferansı Bildirileri. New York, 1996.
Vitae

Sergey Brin , lisans derecesini 1993 yılında Maryland Üniversitesi’nden College Üniversitesi’nden matematik ve bilgisayar bilimleri dalında almıştır. 1995 yılında Stanford Üniversitesi’nde bilgisayar bilimi dalında aday olan 1995’te yüksek lisansını aldı. Ulusal Bilim Vakfı Lisansüstü Bursuna layık görüldü. Araştırma alanları arasında arama motorları, yapılandırılmamış kaynaklardan bilgi çıkarma ve büyük metin koleksiyonları ve bilimsel verilerin veri madenciliği sayılabilir.

Lawrence Page , Michigan, East Lansing’de doğdu ve 1995’te Michigan Üniversitesi Ann Arbor’da Bilgisayar Mühendisliği bölümünden BSE aldı. Halen doktora derecesinde. Stanford Üniversitesi Bilgisayar Bilimi dalında aday. Araştırma ilgi alanlarından bazıları web’in bağlantı yapısını, insan bilgisayar etkileşimi, arama motorlarını, bilgi erişim arayüzlerinin ölçeklenebilirliğini ve kişisel veri madenciliğini içerir.
8. Ek A: Reklam ve Karışık Motifler
Şu anda, ticari arama motorları için baskın iş modeli reklamdır. Reklamcılık iş modelinin
hedefleri, her zaman kullanıcılara kaliteli arama sağlamakla uyuşmaz. Örneğin, prototip arama motorumuzda, cep telefonu için en iyi sonuçlardan biri, sürüş sırasında cep telefonuyla konuşma ile ilgili dikkat dağılmalarını ve riskleri ayrıntılı olarak açıklayan bir çalışma olan ” Dikkatle Cep Telefonunu Kullanmanın Etkisi ” dir. Bu arama sonucu ilk olarak, PageRank algoritması tarafından değerlendirildiği gibi, web’de atıfta bulunma öneminin bir yaklaşımı olan yüksek öneminden dolayı ortaya çıktı [ Sayfa, 98]. Cep telefonu reklamlarını göstermek için para alan bir arama motorunun, sistemimizin ödeme yapan reklamverenlerine geri döndürdüğü sayfayı haklı çıkarmakta zorluk çekeceği açıktır. Bu tür bir nedenden ve diğer medyalarla olan tarihsel deneyimden dolayı [ Bagdikian 83 ], reklam destekli arama motorlarının doğal olarak reklamverenlere karşı ve tüketicilerin gereksinimlerinden uzak durmasını bekliyoruz.
Arama motorlarını değerlendirmek için uzmanlar için bile çok zor olduğu için, arama motoru önyargısı özellikle sinsidir. Bunun için iyi bir örnek OpenText, şirketlere belirli sorgular için arama sonuçlarının başında listelenme hakkı sattığı bildirildi [ Marchiori 97]. Bu önyargı, reklamcılıktan çok daha sinsidir, çünkü kimin orada olmayı “hak ettiği” ve kimin de listelenmek için para ödemeye istekli olduğu belli değildir. Bu iş modeli bir kargaşaya neden oldu ve OpenText uygulanabilir bir arama motoru olmaktan çıktı. Ancak daha az belirgin önyargının piyasa tarafından hoş görülmesi muhtemeldir. Örneğin, bir arama motoru “dost” firmalardan gelen arama sonuçlarına küçük bir faktör ekleyebilir ve rakiplerden gelen sonuçlardan bir faktör çıkarabilir.
Bu önyargı türünün tespit edilmesi çok zordur, ancak yine de piyasa üzerinde önemli bir etkisi olabilir. Ayrıca, reklam geliri, genellikle düşük kaliteli arama sonuçları sağlama konusunda bir teşvik sağlar. Örneğin, büyük bir arama motorunun, havayolunun adı sorgu olarak verildiğinde büyük bir havayolunun ana sayfasını döndürmeyeceğini fark ettik. Bu yüzden, havayolu şirketi kendi adı olan sorguya bağlı pahalı bir reklam vermişti. Daha iyi bir arama motoru bu reklamı gerektirmez ve muhtemelen havayolu şirketinden arama motoruna gelir kaybıyla sonuçlanır. Genel olarak, tüketici açısından, arama motorunun ne kadar iyi olduğu, tüketicinin istediklerini bulması için daha az reklam gerekebileceği tartışılabilir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır.
Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır. Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz. Daha iyi bir arama motoru bu reklamı gerektirmez ve muhtemelen havayolu şirketinden arama motoruna gelir kaybıyla sonuçlanır. Genel olarak, tüketici açısından, arama motorunun ne kadar iyi olduğu, tüketicinin istediklerini bulması için daha az reklam gerekebileceği tartışılabilir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır. Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır. Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz.
Daha iyi bir arama motoru bu reklamı gerektirmez ve muhtemelen havayolu şirketinden arama motoruna gelir kaybıyla sonuçlanır. Genel olarak, tüketici açısından, arama motorunun ne kadar iyi olduğu, tüketicinin istediklerini bulması için daha az reklam gerekebileceği tartışılabilir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır. Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır. Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz. ve muhtemelen havayolundan arama motoruna gelir kaybıyla sonuçlandı. Genel olarak, tüketici açısından, arama motorunun ne kadar iyi olduğu, tüketicinin istediklerini bulması için daha az reklam gerekebileceği tartışılabilir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır.
Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır. Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz. ve muhtemelen havayolundan arama motoruna gelir kaybıyla sonuçlandı. Genel olarak, tüketici açısından, arama motorunun ne kadar iyi olduğu, tüketicinin istediklerini bulması için daha az reklam gerekebileceği tartışılabilir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır. Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır.
Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz. Tüketicinin istediğini bulması için daha az reklam gerekecektir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır. Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır. Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz.
Tüketicinin istediğini bulması için daha az reklam gerekecektir. Bu, elbette mevcut arama motorlarının reklam destekli işletme modelini yıpratmaktadır. Bununla birlikte, bir müşterinin ürünlerini değiştirmesini veya gerçekten yeni bir şeyi olmasını isteyen reklamverenlerden her zaman para olacaktır. Ancak, reklamcılık konusunun saydam ve akademik alanda saydam ve rekabetçi bir arama motoruna sahip olmanın hayati önem taşıdığına dair yeterince teşvik edici olduğuna inanıyoruz.
9. Ek B: Ölçeklenebilirlik
9. 1 Google’ın Ölçeklendirilebilirliği
Google’ı yakın vadede 100 milyon web sayfası hedefine ölçeklenebilir olacak şekilde tasarladık. Kabaca bu miktarda işlem yapabilmek için yeni disk ve makineler aldık. Sistemin tüm zaman alan kısımları paralel ve kabaca doğrusal zamandır. Bunlar, tarayıcılar, dizinleyiciler ve sıralayıcılar gibi şeyleri içerir. Ayrıca veri yapılarının çoğunun genişleme ile incelikle ilgileneceğini düşünüyoruz. Ancak, 100 milyon web sayfasında, yaygın işletim sistemlerinde (şu anda hem Solaris hem de Linux üzerinde çalışıyoruz) her türlü işletim sistemi sınırına çok yakın olacağız. Bunlar adreslenebilir bellek, açık dosya tanımlayıcılarının sayısı, ağ soketleri ve bant genişliği ve diğerleri gibi şeyleri içerir. 100 milyondan fazla sayfaya genişlemenin sistemimizin karmaşıklığını büyük ölçüde artıracağına inanıyoruz.
9.2 Merkezi Endeksleme Mimarilerinin Ölçeklenebilirliği
Bilgisayarların yetenekleri arttıkça, çok büyük miktarda metni makul bir maliyetle endekslemek mümkün hale gelir. Tabii ki, video gibi diğer daha geniş bant yoğunluğu olan ortamların daha yaygın hale gelmesi muhtemeldir. Ancak, metin oluşturma maliyeti video gibi medyaya göre düşük olduğundan, metnin çok yaygın kalması olasıdır. Ayrıca, yakında metni metne dönüştüren ve mevcut metin miktarını genişleten makul bir iş yapan konuşma tanıma ihtimalimiz de olabilir. Bunların hepsi merkezi indeksleme için inanılmaz olanaklar sağlar. İşte açıklayıcı bir örnek. ABD’deki herkesin bir yıl boyunca yazdığı her şeyi indekslemek istediğimizi varsayıyoruz. ABD’de 250 milyon insan olduğunu ve günlük ortalama 10 bin yazdığını varsayıyoruz. Bu yaklaşık 850 terabayt civarındadır.
Ayrıca, şimdi bir terabayt endekslemesinin makul bir maliyetle yapılabileceğini de varsayalım. Ayrıca, metin üzerinde kullanılan indeksleme yöntemlerinin doğrusallıklarını veya karmaşıklıklarında neredeyse lineer olduklarını varsayıyoruz. Tüm bu varsayımlar göz önüne alındığında, 850 terabaytımızı belirli büyüme faktörleri varsayılarak makul bir maliyetle endekslemeden ne kadar süreceğini hesaplayabiliriz. Moore Yasası 1965 yılında her 18 ayda bir işlemci gücünde iki katına çıktı. Yalnızca işlemciler için değil, aynı zamanda disk gibi diğer önemli sistem parametreleri için de oldukça doğru. Moore yasasının gelecek için geçerli olduğunu varsayarsak, ABD’deki herkesin küçük bir şirketin alabileceği bir fiyat için bir yıl boyunca yazdığı her şeyi endeksleme hedefimize ulaşmak için sadece 10 katına veya 15 yıla ihtiyacımız var.
Tabii ki, donanım uzmanları biraz endişeli Moore ‘
Tabii G gibi dağıtılmış sistemler l ÖSS [ Gravano 94 ] veya Hasat genellikle indeksleme için en verimli ve zarif teknik çözüm olacak, ama bunun sebebi yukarı büyük ayarlama yüksek yönetim maliyetleri bu sistemleri kullanmaya dünyayı ikna etmek zor görünmektedir tesislerin sayısı. Elbette, yönetim maliyetini büyük ölçüde düşürmenin mümkün olması oldukça muhtemeldir. Bu olursa ve herkes dağınık bir indeksleme sistemi çalıştırmaya başlarsa, arama kesinlikle ciddi şekilde gelişir.
İnsanlar yalnızca sınırlı bir miktar yazabildiklerinden veya konuşabildiklerinden ve bilgisayarlar gelişmeye devam ettikçe, metin dizine alma işlemi şimdi olduğundan daha iyi ölçeklenir. Elbette, sonsuz miktarda makine tarafından oluşturulan içerik olabilir, ancak yalnızca büyük miktarlarda insan tarafından oluşturulan içeriğin dizine alınması çok yararlı görünüyor. Bu nedenle, merkezileştirilmiş web arama motoru mimarimizin zamanla ilgili metin bilgilerini gizleme kabiliyetinde gelişeceği ve arama için parlak bir gelecek olduğu konusunda iyimseriz.
Tabiki yukarıdaki Google Algoritmasının sunumu 1995 yılında kullanılan ve günümüzde ki düşünen akıllı Google algoritması ile alakası yoktur. Günümüzde Google yapay zeka teknolojileri ile kendi kendine öğrenebilen bir yapıya kavuşmuştur ki aslında SEO sektörünün devamında dijital pazarlamanın gelişmesinin temelinde hep büyük sitelerin kullandıkları yapay zekalar yatmaktadır. Aksi durumda 3-5 web sitesi altına footer linkleri ekleyerek SEO yapmaya devam ederdik değil mi…











